Automating project management with deep learning

How natural language processing can be used to classify project status updates
Introduction
In the data-driven future of project management, project managers will be augmented by artificial intelligence that can highlight project risks, determine the optimal allocation of resources and automate project management tasks.
For example, many organisations require project managers to provide regular project status updates as part of the delivery assurance process. These updates typically consist of text commentary and an associated red-amber-green (RAG) status, where red indicates a failing project, amber an at-risk project and green an on-track project. Wouldn’t it be great if we could automate this process, making it more consistent and objective?
In this post I will describe how we can achieve exactly that by applying natural language processing (NLP) to automatically classify text commentary as either red, amber or green status.
Training a project management language model
To ensure our RAG status classifier achieves good results, we first need to build a language model that understands the specific language used by project managers.
Only a few years ago, it would have required a huge corpus of text and a significant amount of compute power to train a custom project management language model. However, recent advances in applying transfer learning to NLP allows us to train a custom language model in a matter of minutes on a modest GPU, using relatively small datasets.
In transfer learning, we take the weights learned by a model trained on a large, general dataset and use them as the starting point to train a new model on a different dataset. This is an extremely useful technique, since it allows us to train high performance language models when we have limited data available.
Mudano has collected a small (but rich) dataset of project status updates across a number of large IT transformation projects. We will use this dataset to first train a custom project management language model and then train the RAG status classifier.
Exploring the data
We start by loading the data into a pandas.DataFrame and having a look at an example project status update. Our data is stored in a .csv format, consisting of a column of text commentaries and a column of the associated RAG statuses. We can load it as follows:

and look at an example text commentary at random from our dataset:

All activities continue to plan with Stage Gate approval.\n\nAnalysis on the Database has completed and options are currently under assessment to bring the system into compliance. Once complete a Request will be raised to bring the system into the scope of the project.\n\nA down stream impact has been identified in that should an enquiry be made for information after it has been deleted in source systems, a null response will be returned. Investigations are underway to understand if this impact is acceptable or if action is needed.
All activities continue to plan with Stage Gate approval.\n\nAnalysis on the Database has completed and options are currently under assessment to bring the system into compliance. Once complete a Request will be raised to bring the system into the scope of the project.\n\nA down stream impact has been identified in that should an enquiry be made for information after it has been deleted in source systems, a null response will be returned. Investigations are underway to understand if this impact is acceptable or if action is needed.

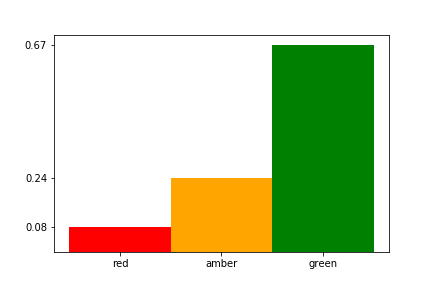
As we suspected, a green status update is significantly more likely than an amber status update, and a red status update is the least likely. We will need to take this class imbalance into consideration when we train our RAG status classifier.
Getting started with deep learning
Now that we have explored our data, we can model it using machine learning. Deep learning is a branch of machine learning that uses deep neural networks trained on large datasets, and is particularly well suited for tasks like language modelling and text classification. To build our deep learning models we will use the fastai library.
fastai is a high-level deep learning library that greatly simplifies the training of deep neural networks for typical machine learning problems, such as image and text classification, image segmentation and collaborative filtering.
To install the fastai library, we can simply use the conda package manager, as follows:

We can then import the main fastai library and the fastai.text module:

Loading data into fastai
Now that we have imported the fastai.text module we can use its built-in functions to easily load and process our data. Since our data is text-based and in .csv format, and since we are building a language model, we use the TextLMDataBunch.from_csv function to load and process our data into a databunch:

Amazingly, that’s us ready to train our custom language model!
Before we do that though, it’s worth spending a bit of time digging into the clever data processing fastai has done behind the scenes.
Tokenization, numericalization and split
Unlike image data, raw textual data can’t be directly fed into a machine learning model and needs to be processed into a numerical format. To do that, we need to split the text into tokens that can then be assigned numerical values.
Text tokenization is done at the word-level by default in fastai.text, with punctuation and contractions of words included in the tokenization. fastai.text also automatically removes HTML symbols and adds in special tokens to replace unknown tokens.
Once the text has been tokenized, fastai.text then converts the list of tokens to integers and calculates the frequency of occurrence of each token. By default, fastai.text keeps the 60,000 most frequent tokens and removes tokens that occur less than twice in the text. These tokens are the vocabulary used to train the language model. In our case, due to the relatively small dataset, we only have a vocabulary of 994 tokens.
fastai also handily splits the data into training and validation sets for us.
Training a custom language model
We build our custom language model by defining a language learner object in fastai:

We use the databunch we defined previously (data_lm) and a pretrained language model (pretrained_model=URLs.WT103) as input to the learner object, and set the dropout to 0.5 to avoid overfitting (drop_mult=0.5).
fastai.text uses an AWD-LSTM model by default and we have chosen to leverage transfer learning by providing a pretrained model that was trained on the WikiText-103 dataset.
To start training our model, we need to decide on an appropriate learning rate. Luckily, fastai has some really useful built-in tools that make it very easy to select an optimal value for this.
We can use the fastai learning rate finder (which runs a series of mini-training jobs over a range of learning rates) and then plot the loss versus the learning rate:

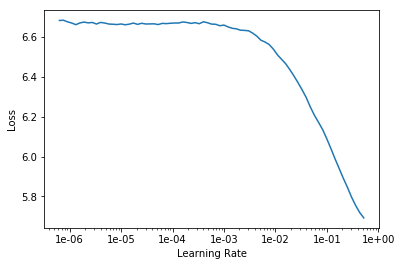
We then select a learning rate just before the minimum loss, as recommended by Jeremy Howard in the fast.ai Practical Deep Learning for Coders course. From the plot above, I decided on a learning rate of 1e-01.
To train our model we simply call the fit_one_cycle method from our learner object, input the number of epochs we want to train over (in this case 20) and the optimal learning rate we found using the learning rate finder:

With our relatively small dataset, training over 20 epochs only took a few minutes on an Nvidia Tesla K80 GPU and gave a validation perplexity score of 34.3.
Not bad! But we can definitely improve on this.
In that first training run we were only training the last layer of the LSTM model. The fastai library allows us to ‘unfreeze’ earlier layers of the model and train them too.
In our second training run, we will fine-tune our model using a lower learning rate and decaying the learning rate for earlier layers in model using the slicefunction:

The intuition behind this is that earlier layers in the model have learnt fundamental aspects of language, so we don’t want to change these very much.
After unfreezing the earlier layers of the model and training using a decaying learning rate over 20 epochs we get a validation perplexity score of 3.3.
Let’s see how our custom project management language model does at generating project update commentaries:

This project is now completed and is currently in the process of working.
That is pretty amazing! The model understands grammar and punctuation, and is using project management specific words in the right context.
Let’s save the custom language model encoder to use in our classifier:

Training a RAG status classifier
Now we have a custom project management language model, we can build a model to classify text commentary as either red, amber or green status.
The first thing we need to do is create a text classification databunch, just like we did when we trained our language model:

To create a text classification databunch, we need to provide the function with our custom language model vocabulary (vocab=data_lm.train_ds.vocab) and the training batch size (bs=32).
Next, we define a text classification learner object, using the text classification databunch as input and setting dropout at 0.5:

Then we load the custom language model encoder we saved earlier:

We are now in a position to start training our RAG status classifier, but to ensure we get good results, we need a way to deal with the significant class imbalance we noticed when exploring the data. If we don’t deal with this, it’s likely that the classification model will simply learn to predict the majority class (green) for any text commentary we input.
One way we can deal with a class imbalance is to calculate the balance of the different classes and use the inverse of this to weight the loss function for each of the different classes i.e. a class is penalised if it occurs more frequently.
This is just the inverse of the class_imbalance we calculated when we were exploring the data and can be easily inputted into our cross-entropy loss function:

Now we have dealt with the class imbalance, we can train our RAG status classifier. We follow exactly the same procedure as we did for training our custom language model.
First we run the fastai learning rate finder and plot the results:


Then we start training the classifier model using the optimal learning rate (1e-2, taken from the plot above) and the number of epochs we have chosen to train over (20):

Since this is a highly imbalanced multi-class classification problem, we can’t use accuracy as the performance metric for our model. Instead, we will use the micro F1 score as our performance metric, which takes into account precision, recall and the class imbalance.
After this initial training cycle, our classification model achieves an F1 score of 0.77. We unfreeze the earlier layers and fine-tune our model:

And that’s us! We have a RAG status classifier that uses a custom project management language model and achieves an F1 score of 0.79.
Let’s see how the RAG status classifier does when we feed in a text commentary example from a project update.
Classification example
Data Milestone 31/05 will not be achieved with current re-plan date under review. This is due to data ingestion challenges, specifically ‘sync sort’ data migration issues, platform complexity and IT release governance process to go live.
Solution Milestone at risk due to continued data sourcing delays created by technical SME availability; escalations continue to prioritise programme with Group IT and Technical
Work is progressing to map out processes, agree the tools to be used on the programme and identify feasibility of process improvements, logical groupings for delivery to feed into an optimised plan.

Our model correctly classifies the text-based commentary above as a redstatus update, and it certainly reads like a red status!
Conclusion
In this post I’ve taken you through how you can build a deep learning text classifier, using a custom language model trained on a relatively small dataset with transfer learning.
By leveraging the functionality of the fastai library, we now have a custom project management language model and RAG status classifier that we can use to automatically determine the status of projects based on text commentaries.
This is just one example of how Mudano is enabling project managers to focus on what’s really important by using machine learning to automate project management tasks.
Do you want to work on similar projects for some of the world’s biggest companies? Or help develop products that enable the autonomous project? If so, then check out Mudano’s Client-facing Data Scientist and R&D Data Scientist open positions here or get in touch with me on LinkedIn.