How Machine Learning is Helping the Financial Services Industry Catch the Bad Guys

Financial crime costs businesses and individuals billions – in the UK alone, this amounts to over £24 billion per year[1]. And this figure doesn’t even consider the operational overheads for businesses to actively monitor and investigate cases across multiple compliance regimes. With an ever-changing regulatory landscape and criminals evolving their techniques to try and stay one step ahead, this creates a perfect storm: financial losses, spiralling costs and heightened regulatory risk.
Despite massive investment in software solutions, most financial crime prevention processes are still based on basic, static rules and generate a lot of wasted manual effort. Teams on the ground, although highly specialised are often facing systemic challenges, including:
- High volumes of false positive alerts driving wasted investigations
- Increasingly complex customer behaviour
- Regulatory pressure to demonstrate quality and consistency in investigations
- Poor customer data quality
The status quo is obsolete. It is slow to react, high cost and increasingly inefficient at actually spotting suspicious activity, screening businesses or individuals and preventing market abuse.
How Machine Learning is changing the landscape
Machine Learning (ML) can and is fundamentally changing this picture: reducing cost and making the best use of a bank’s resources. But that’s what 100 other consultancies would say. We’re different because we’re not only at the forefront of ML, publishing papers and generating novel techniques, we balance this behavioural science and systems engineering knowhow to implement at pace in what we like to call Delivery Science™️.
We’ll help you start small but think big by placing ML at the centre of the value chain instead of just trying to automate existing processes. The Head of Financial Crime Operations at leading global bank hit the nail on the head when he described the current trend of Process Automation as just “automating stupidity”. Requiring only historic expert decisions and the underlying data you already have, we can remove the need to continually define and maintain rules – instead only desired outcomes need to be specified, such as your previously identified suspicious transactions and PEP watchlist matches. This approach can significantly reduce operational overheads through reduced numbers of false positive alerts and intelligent triage. Importantly however – and this is where we bridge research and reality – we take significant steps to ensure that this machine intelligence is implemented in a low regulatory risk manner.
A key argument against using ML to detect financial crime has been the lack of model explainability, particularly in regard to the more advanced techniques such as deep learning. That is, the ML model being a black box that magically returns decisions, with little to explain why. This has traditionally created a highly cautious approach or abrupt refusals to even engage with ML from leading compliance and risk stakeholders. But the tide is turning. First, leading banks and hedge funds are showing huge amounts of value from using ML in revenue generation, making ML feel a little more real in the institution. Second, but more importantly, there have been significant advances in the field of explainability – so much so that it emerged as a key theme from this year’s Neural Information Processing System (NeurIPS) conference[2], the largest and most famous AI conference in the world. A range of techniques now exist including code libraries that identify which features in your data were most important in defining the result, working out how sensitive your model is to changes in the input features and defining the difference in inputs needed to switch the model prediction (e.g. from ‘suspicious’ to ‘not suspicious’). Figure 1 summarises how explanatory models are being implemented in partnership with a predictive model. Since attending the conference, our researchers have been hard at work building these techniques into their experiments – making individual case explainability a reality on the ground.
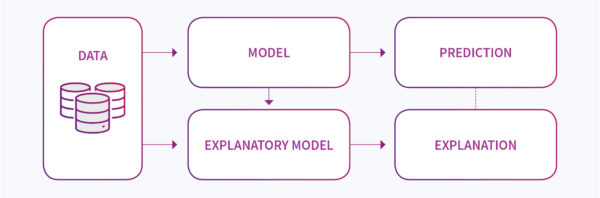
Figure 1: How explainability is becoming the new norm within ML architectures particularly in regimes where just trusting a black-box is just not going to fly. Financial Crime detection is a significant driver for these developments.
So, with ML an emerging trend in Financial Crime prevention, where is it being applied across the value chain? With such a wide field to explore, we’ll keep it simple here and focus on the operational activities of alert generation and triage, then case investigation and reporting – see figure 2. First, in alert generation, models trained on historical records of alerts are improving accuracy by reducing false positives, but at the same time keeping the model trained to handle the most recent transaction behaviours. For example, our unique algorithm for suspicious transaction detection makes use of active learning techniques to not only detect suspicious transactions but also find customer activity that is most able to improve the model. This enables the model automatically stay as fresh and relevant as the day it was implemented. By plugging in explanatory models into such algorithms, we can also begin to give the triage team contextual information as to why the alert is occurring.
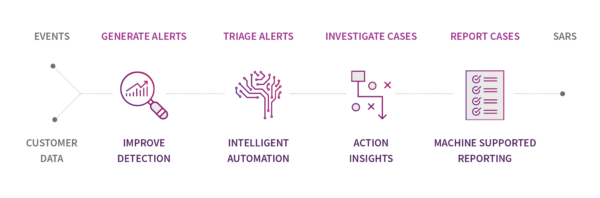
Figure 2: The Operational Value Chain for Financial Crime Detection
By applying ML to help with alert triage, businesses can make quick gains in operational efficiency, while still relying on their existing rule-based models. We find this is a great entry point as it keeps the regulatory risk low while confidence is built in the models – only later do we tend to switch to generating novel alerts. Our state-of the-art algorithm applicable to PEP screening builds on the latest research and is showing that up to 50% of alerts can be closed automatically even with messy, poor quality data inputs – without generating any false negatives. Such an advance can significantly reduce manual overheads, without increasing the risk of missing true cases.
The next phase of our research – and therefore what we can shortly bring into reality – will focus on supporting the case investigation process. For example, using natural language processing and alert information to conduct intelligent case assignment – automatically choosing the best suited SME for further investigation based on risk and complexity. By bringing historical cases into our training data set, we further postulate that we’ll be able to automate a significant amount of the case reporting by pre-populating reports with rationale built on the explanatory models, but this time outputting natural language into draft reports.
Advances in ML are revolutionising financial crime detection and avoid that perfect storm: operational costs are being reduced through increased model accuracy; explanatory models are keeping regulatory risk low; and by taking the grind out of detection, a more motivated and engaged team with more time per alert and case, the tide is beginning to turn in the fight against those lost billions.
[1] https://nationalcrimeagency.gov.uk/what-we-do/crime-threats/money-laundering-and-terrorist-financing.
[2] https://towardsdatascience.com/a-review-of-neurips-2018-89cf3f38a868
Fin Crime costs businesses and individuals billions every week. Deep Learning can be a real weapon in the fight to reverse the trend. Here are some simple ways to get to see the wood for the trees through reduction of false-positives leaving you free to tackle the real bad guys. Other ML based experimentation includes… But why stop there. In Scotland, we’ve been inspired by DI Eamonn Keane’s attitude – more used to catching murderers, he’s recognised that cyber and fin crime has left the modern police force with a real problem – now he has re-trained in technology at the Data Lab and we are working on ways to help him and banks REALLY catch bad guys, not just reduce the losses.