Review of NeurIPS 2018 – the most famous AI conference in the world

Using our personal development budgets, a great scheme offered by Mudano, we attended last year’s Neural Information Processing System (NeurIPS) conference in Montreal. This is the largest and most famous AI conference in the world, now in its 32nd year, and attended by over 8500 people. Registration sold out within minutes, so we were very lucky to secure our places!
It was an intense six days filled with tutorials, workshops and presentations in all areas of machine learning. We learnt about the latest cutting-edge research, and about how technology companies across the world are using and developing machine learning tools.
Besides the big names, such as Google, Facebook and Microsoft, we had interesting discussions with researchers from a number of small startups, many of which work on problems similar to those we tackle at Mudano. We also spoke to data scientists in the big consultancies and financial services companies, such as EY and J.P. Morgan, and heard how they are taking advantage of data science and machine learning.
Here are some of the key themes from the conference and things we learnt over the course of the week.
Explainability is essential
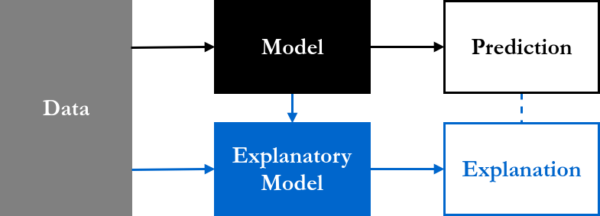
As models become more sophisticated, so grows the need for being able to understand and trust them. An excellent plenary talk was given by Prof. Spiegelhalter from University of Cambridge who described the careful use of statistics in his team to explain and validate algorithms for the diagnosis and recommendation of treatment in breast cancer, such that the patients will trust the models and ensure the best possible outcome.
In financial services where data scientists tackle problems such as credit lending and fraud detection, it is also very important to understand the reasons behind the decisions made by machine learning algorithms. In the ‘AI in Finance’ workshop, more than ten posters out of thirty were devoted to the subject of model explainability.
For a recent prototype, we used a new Python library called ‘shap’ to explain which features played the largest role in a classification problem. We discussed this with other machine learning researchers at the conference, who agreed that this is a very good library to use for explaining feature importance on a local and global level. The algorithm works by applying game theory (a branch of mathematics) to develop exact tree solutions to identify unique and consistent feature importance of machine learning models for predicting each class. (In the example below age=37 is making it more likely that the candidate receives the loan.) This will become part of our toolkit in explaining our machine learning models. Since ‘shap’ is a Python library, our client facing data scientists can also easily access it.

Another interesting approach is to use the sensitivity of a model with respect to its inputs to assess feature importance. It is particularly useful in neural networks since they are inherently differentiable and allow the aggregation of the derivatives (sensitivity) to identify local and global behaviour of the model. Authors from J.P. Morgan demonstrated a sensitivity-based method using a credit card default dataset and produced an open-source Python package to be distributed soon.
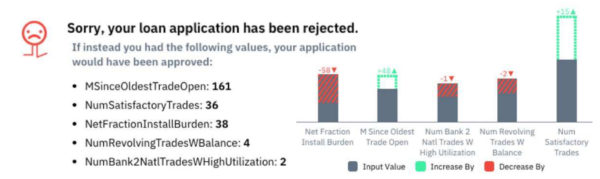
A different way of tackling explainability is through the use of counterfactuals. In this method minimum change in the set of input vectors that flips the result of the classifier is calculated. For example, in the problem of determining the outcome of credit applications, once a classifier is built, we can find the smallest change to the set of input variables of an applicant (e.g. salary, age, previous applications) that leads to the opposite prediction outcome, and weigh their relative importance to inform the applicant the reason why their application was rejected. This is a very intuitive idea, so we will implement this method and share with other teams in Mudano.
In addition to explainability, other research that may be of interest to us include how to use active learning to assign risk scores, novel methods of resampling and learning from imbalanced data, automatic classification of customer due diligence from text-based reports using textCNN. These are only a few examples and we are in the process of sifting through the conference papers to find other interesting ideas.
Machine learning requires software engineers
Machine learning as a service has gained significant traction in the last few years. We talked to a number of successful startups, including Element AI, Borealis AI and Stratigi, that have evolved from consultancies to machine learning software providers.
These companies identify market need and build machine learning products that are then sold to their clients. This means a single product can be sold to multiple buyers, allowing the R&D researchers time to carry out more innovative research and stay ahead of competitors.
The most striking common characteristic between these successful companies is that the machine learning research is well-supported by a team of software developers and data engineers that can build robust, efficient and marketable products. This is because while machine learning scientist have devoted years in researching and developing cutting edge algorithms, data engineers and software developers have spent similar amount of time building fully developed products that are efficient, compact and robust on all types of platforms. They are able to put protypes into production in a fraction of the time taken by machine learning scientists because this is where their expertise lies.
At QuantumBlack (a subsidiary of Mckinsey & Company) the ratio of developers to data scientists is approximately 1-to-1, while at some of the more product-based companies the ratio is closer to 2-to-1. Making the most of cutting edge research requires the support of expert engineers that can develop products and build secure infrastructure.
Deepmind (and the rest)
Unsurprisingly, some of the best talks came from Deepmind, especially their collaboration with Moorfield hospital in the detection of retina diseases, which appeared in the journal Nature in September. Just prior to the conference, Deepmind introduced DeepFold, a pretrained model for efficient protein structure search, which is essential in drug discovery.
Boris met with the AlphaZero team, which was responsible for creating a Reinforcement Learning autonomous agent that mastered the most complex two player fully observable zero sum games — Go, Chess and Shogi — with no prior knowledge. The algorithm starts playing games against itself randomly, then learns a policy for which moves are most promising given a current position, and a value function which estimates the win probability in each position. Then it repeats the process, this time using the learned policy and value functions to play against itself. Then it retrains again, and four hours (and millions of games) later, it’s stronger than any human or human crafted chess engine.
The AlphaZero team revealed some information that was previously unknown — their testing game was a smaller sized Go game, commonly played by beginners, but far from solved by professional players. The game was thought to be nearly as complex as chess, but AlphaZero learns / solves the game completely, obtaining a 100% win rate with white colour.
The plenary sessions were on more general aspects of Artificial Intelligence and machine learning. We went to talks on how to interact with public policymakers, how to make research reproducible, and how machine learning will affect the development of software. One of the most fascinating talks was about bioelectric computation outside the nervous system, such as how to create multi-headed worms by just modifying the ion channels. It is completely outside the domain of traditional machine learning! These talks invited us to reflect on the role of AI in society, remind us that research need rigour to be trustworthy, and to think outside the box — and be excited about the future!
Future of machine learning research at Mudano
Machine learning, in particular deep learning, has now achieved a level of maturity that it’s being used to solve many industry problems. Research and development is still advancing at a rapid pace in a wide range of subject areas, but a few key themes were prominent at NeurIPS 2018:
- Due to the success in games such as Chess, Poker and Go, Reinforcement Learning is a now a major field, with more than four sessions devoted to it and the largest workshop attendance. With the amount of investment in this field we can see it having a long term future.
- People are more interested in explainable AI, which leads to tutorials and workshops on Causal Learning, an area that is very relevant to Mudano.
- We need a coherent way of dealing with uncertainties, both in models and data, there is continued interest and research into Bayesian methods.
Over the next few months we will be deep diving into these topics and develop our understanding of how they can be applied to solve machine learning problems in Mudano.
We are fortunate to have many world-leading machine learning researchers in Scotland, particularly in the Informatics department in the University of Edinburgh. We met a few of them at the conference and learnt about their research interests, which include reinforcement learning, multi-task learning and Bayesian networks.
They are always open to new ideas and many of their PhD students have industrial sponsors. This might be a way to establish closer connections with universities and bringing in knowledge and expertise to Mudano.
Conclusion
We had a great time in Montreal, it is a beautiful city and charming in its Frenchness. It was a busy week, but it was also fun. The size of the conference made it possible to meet many interesting people, regardless of which fields they worked in. We also had fun at the demos: amongst other things, people showing how their humanoid robots that respond to voice commands to pick up things; how to use ML to teach people to play a Bach fugue, how to learn to play competitive adversarial games and how to learn to dance using ML, real time 2D/3D super resolution.

Boris in particular played many games of Chess and Go (and won the majority of them!) and made friends along the way. One Chess and Go player was a German Intelligence researcher, focusing on the problems of cryptography. He offered an interesting insight, which was that if you care about your secrets ~15 years down the line, then current encryption methods are inadequate.
The rationale is that current encryption methods can easily be broken by 500–2000 quantum bit computers, which are expected to be available in ~15 years, and the attacker might patiently store your current encryption communications, with knowledge that at a later date they’ll be able to decrypt them. Not all is bleak, as quantum attack resistant methods already exist.
This trip gave us a wonderful opportunity to interact with the deep learning community. We learnt about what the most interesting problems are, who are leaders in particular fields, and what data science companies are doing. All of these would have been difficult to learn at home. It has certainly broadened our horizons and will definitely add value to the data science and machine learning at Mudano. We took lots of notes throughout the conference and anyone is welcome to talk to us if they are interested in learning more about the conference or machine learning in general!